Transformez votre web en machine à clients.
Nous aidons les artisans, commerçants et TPE partout en France à obtenir plus d'appels et de clients qualifiés grâce au digital.
Déjà 50+ entreprises accompagnées
Trouvez votre ville parmi nos secteurs d'intervention
Nous intervenons partout en France pour booster votre visibilité locale.
Votre ville n'apparaît pas ? Contactez-nous.
Ce que nos clients obtiennent concrètement.
Plus d'appels entrants
Nos clients constatent une hausse de +45% d'appels qualifiés en moyenne après 3 mois.
Ciblage Précis
On touche les clients qui cherchent EXACTEMENT ce que vous vendez, dans votre zone.
Image de Marque
Un site moderne et une fiche Google impeccable renforcent immédiatement votre crédibilité.
Visibilité Dominante
Soyez présent partout : site web, Google Maps, annuaires. Ne laissez aucune chance au hasard.
Gain de Temps
On gère tout : technique, mises à jour, optimisation. Vous vous concentrez sur votre métier.
ROI Mesurable
Pas de flou artistique. Vous savez combien vous investissez et combien ça vous rapporte.
Nos Solutions
Des services pensés pour les acteurs locaux.
Landing Page
Une page unique conçue pour convertir. Idéale pour une campagne publicitaire ou le lancement d'un produit.
- Design haute conversion
- Formulaire optimisé
Site Vitrine
La carte de visite digitale de votre entreprise. Présentez vos services et rassurez vos prospects.
- 5 à 20 pages optimisées
- Rédaction SEO incluse
E-commerce
Vendez vos produits 24h/24. Une boutique en ligne clé en main, sécurisée et facile à gérer.
- 0% frais de transaction
- Gestion des stocks
Google My Business
Dominez le Pack Local Google Maps. Nous optimisons les facteurs de classement pour vous placer devant.
- Posts hebdomadaires
- Optimisation mots-clés
Référencement SEO
Votre site web sera optimisé pour le référencement Google. Grâce à l'audit préliminaire, vous serez positionné sur les mots clés qui comptent vraiment.
- Devenir la référence sur Google
- Optimisation de tout le site
Pages Locales SEO
Apparaissez en 1ère page de Google dans chaque ville où vous travaillez. Vos clients vous trouvent partout.
- Création multi-villes
- Stratégie de maillage
Appels entrants moyens
Position Google Maps
Croissance trafic web
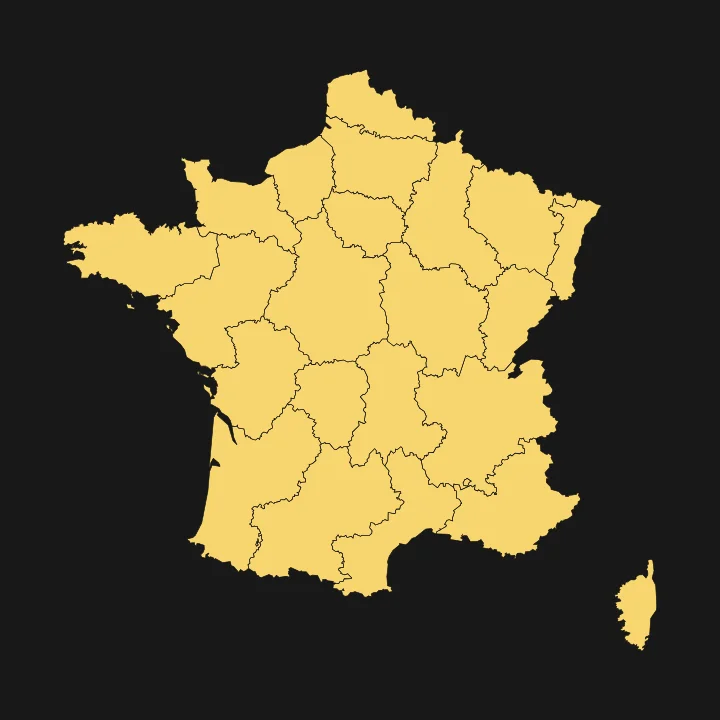
Zone d'intervention
Nous couvrons toute la France.
Basés à Six-Fours-les-Plages (83), nous accompagnons des entrepreneurs ambitieux dans toute la France. Que vous soyez à Marseille, Lyon, Paris ou dans un village de la Drôme, le digital n'a pas de frontières.
Nous gérons votre visibilité à distance avec la même efficacité et la même proximité humaine que si nous étions voisins.
Vos questions
Tout ce que vous devez savoir.
Actualités
Derniers articles
SEO LOCAL • 09 Janv 2026
Comment valider sa fiche Google My Business rapidement
Les nouvelles règles de Google pour valider sa fiche et apparaître...
SEO LOCAL • 05 Oct 2025
Qu'est-ce que la Géolocalisation SEO ? Définition simple
Comprendre simplement la Géolocalisation SEO et son rôle dans...
GOOGLE MY BUSINESS • 28 Sept 2025
Créer une fiche Google My Business en 2026 : guide étape par étape
La méthode claire pour être visible localement dès le départ...
Contactez-nous
Prêt à décoller ?
Remplissez ce formulaire pour recevoir votre audit gratuit ou demander un devis. Réponse garantie sous 24h.
AWL - Agence Web Local
180 rocade font de fillol,
83140 Six-Fours-les-Plages, France